Recursive Language Models (RLMs)
Paper: Zhang, Kraska & Khattab — MIT CSAIL, January 2026
Code: github.com/alexzhang13/rlm
TLDR;
From first principles — before RLMs, performance degradation over large contexts was a known issue. RLM addressed this by saying: "I will write code to split the large context into meaningful chunks, and for each chunk I will call an LLM. That sub-LLM call can itself further split and call recursively."

Your one-line summary is actually the cleanest way to state the paper's core idea:
"I will write code to split the large context into meaningful chunks, call an LLM on each chunk, and that sub-LLM can itself split and call further."
The three eras the paper is responding to are exactly:
Era 1 — Vanilla LLM: Just stuff everything into the window. Works until the context gets long, then quality collapses — the paper calls this context rot. The model attends poorly to tokens far back in the sequence.
Era 2 — Compaction/summary agents: Split and summarise as you go. Slightly better, but lossy — once you summarise chunk 1, those details are gone forever. Fails for tasks that need every part of the document.
Era 3 — RLM: Don't put the context in the window at all. Store it as a variable in the REPL. The root LLM writes code to selectively inspect only what it needs, calls sub-LLMs on those pieces, and those sub-LLMs can do the exact same thing again. Nothing is discarded — everything remains accessible in the REPL variable at all times.
The elegant thing is that the recursion is not designed by a human — the model itself decides how to split, how deep to go, and when a chunk is small enough to answer directly. That's what makes it general purpose rather than task-specific.
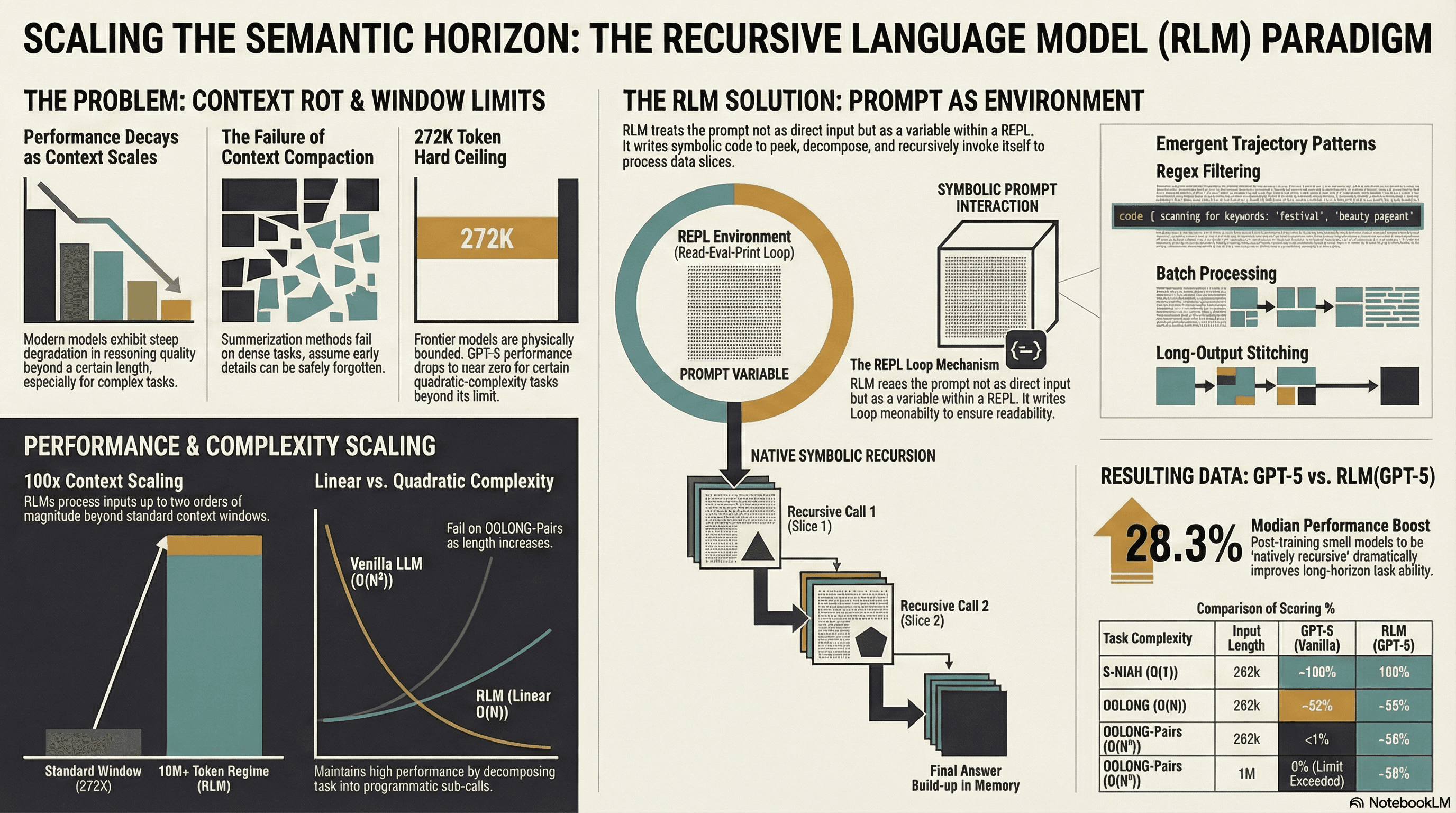
The Problem: Context Rot
Frontier LLMs have a fixed context window. When you stuff a very long prompt into it, quality degrades steeply — the model attends poorly to tokens far back in the sequence. The paper calls this context rot.
The two approaches before RLMs both fell short:
| Approach | What it does | Limitation |
|---|---|---|
| Vanilla LLM | Feed the entire prompt directly into the window | Window fills up; context rot kicks in |
| Compaction / summary agents | Summarise chunks as context fills | Lossy — early details are permanently discarded |
Neither approach works for tasks that need dense access throughout the full document — things like aggregating every line of a dataset, understanding an entire codebase, or reasoning across millions of tokens.
The RLM Idea — From First Principles
The core insight is simple:
Don't put the large context into the LLM's attention window at all. Store it as a variable in an external environment. Let the LLM write code to split it into meaningful chunks, then call itself on each chunk. Each sub-call can itself split and call further.
This is the recursive part — the same model appears at every level of the tree, calling itself until chunks are small enough to answer directly.

How It Works
1. The REPL Environment
When an RLM receives a long prompt P, it does not feed P to the LLM. Instead:
state["context"] = P # stored as a variable
hist = [Metadata(state)] # only length, prefix, structure given to LLM
The LLM never sees the full text. It only knows the context exists as a variable. To read it, the model must write code:
chunk = context[:50000]
result = llm_query(f"Summarise this: {chunk}")
The REPL executes that code and returns only a short truncated stdout back to the model — forcing it to use variables and sub-calls to manage long content rather than printing everything into its window.
2. The llm_query() Function
The REPL is initialised with two things:
context— the full prompt as a string variablellm_query()— a function that is itself a sub-RLM call
This means the model can write loops like:
chunks = [context[i:i+50000] for i in range(0, len(context), 50000)]
results = [llm_query(f"Answer this about the chunk: {c}") for c in chunks]
final = llm_query(f"Combine these: {results}")
Each llm_query() call is a full RLM invocation — same loop, same REPL, same ability to recurse further.
3. The RLM Loop (Algorithm 1)
state ← InitREPL(prompt=P)
state ← AddFunction(state, sub_RLM) # inject itself as callable
hist ← [Metadata(state)]
while True:
code ← LLM(hist) # model writes code
state, stdout ← REPL(state, code) # code runs, may call sub_RLM
hist ← hist + code + Metadata(stdout)
if state["Final"] is set:
return state["Final"]

The Recursion Tree
For a 10,000-page document:

Root LLM (10,000 pages — too large)
├── Sub-LLM 1 (100 pages — still too large → splits again)
│ ├── Sub-Sub-LLM 1.1 (10 pages — fits → answer)
│ ├── Sub-Sub-LLM 1.2 (10 pages — fits → answer)
│ └── ...merge → section 1 summary
├── Sub-LLM 2 (100 pages — fits → answer directly)
├── ...
└── Sub-LLM N (100 pages — fits → answer directly)
↓
Root merges all results → FINAL answer
The split is not uniform — the root LLM uses code (regex, keyword search, structural markers) to intelligently decide how to slice the context. It might fetch only documents containing a keyword, or split by Markdown headers, or chunk by newlines.
When Does It Stop Splitting?
Two stopping conditions:
1. Natural base case — the chunk fits comfortably in the sub-LLM's context window. The model answers directly. No further splitting needed.
2. Hard depth limit — a maximum recursion depth is enforced as a safety guardrail. In the paper's experiments, depth was set to 1: sub-LLMs could not split further and were treated as plain LLM calls.
There is no explicit "is this small enough?" check baked into the system — the model itself learns to judge this through prompting or fine-tuning. This is why weaker models like Qwen3-8B struggled as RLMs without fine-tuning: they didn't reliably know when to stop splitting vs when to just answer.
Key Design Choices vs Naive Approaches
The paper contrasts RLMs with a "similar-looking" Algorithm 2 that is far less expressive:
| RLM (Algorithm 1) | Naive agent (Algorithm 2) | |
|---|---|---|
Where does P live? |
REPL variable — never in LLM window | Directly in hist — window fills immediately |
| How are outputs generated? | Via REPL variables — unbounded length | LLM generates directly — bounded by window |
| Sub-calls | Programmatic — inside loops, Ω( | P |
Results
RLMs were evaluated on four tasks of increasing complexity:
| Task | Complexity | RLM (GPT-5) | Base GPT-5 |
|---|---|---|---|
| S-NIAH (needle-in-haystack) | O(1) | Strong | Strong (within window) |
| BrowseComp+ 1K docs | Linear | 91.3% | 0% (can't fit in window) |
| OOLONG | Linear | 56.5% | 44.0% |
| OOLONG-Pairs | Quadratic | 58.0% | 0.1% |
Key findings:
RLMs handle inputs up to 2 orders of magnitude beyond the model's context window
On information-dense tasks, RLMs outperform all baselines by double-digit percentages
Median inference cost is comparable to or cheaper than a base model call
A fine-tuned 8B model (RLM-Qwen3-8B) outperformed base Qwen3-8B by 28.3% on average
Emergent Patterns in RLM Trajectories
Even without task-specific training, RLMs develop consistent strategies:
Regex filtering — use code to search for keywords before calling sub-LLMs, avoiding unnecessary processing
Batch chunking — split by newlines, headers, or fixed character counts and process in parallel
Variable stitching — for long-output tasks, store sub-call results in variables and concatenate into a final answer
Limitations
Sub-calls are currently synchronous and blocking — async calls would dramatically reduce runtime
Max recursion depth of 1 was used — deeper recursion is unexplored
Models without strong coding capabilities struggle as RLMs
Thinking models can run out of output tokens mid-trajectory if reasoning tokens are too long
One-Line Summary
An RLM stores the prompt as a code variable, writes a program to split it into chunks, calls itself on each chunk, and each sub-call can split further — stopping only when a chunk fits in the context window or the recursion depth limit is hit.