What is HyDE

The core question is: what makes zero-shot retrieval fail, and what would fix it?
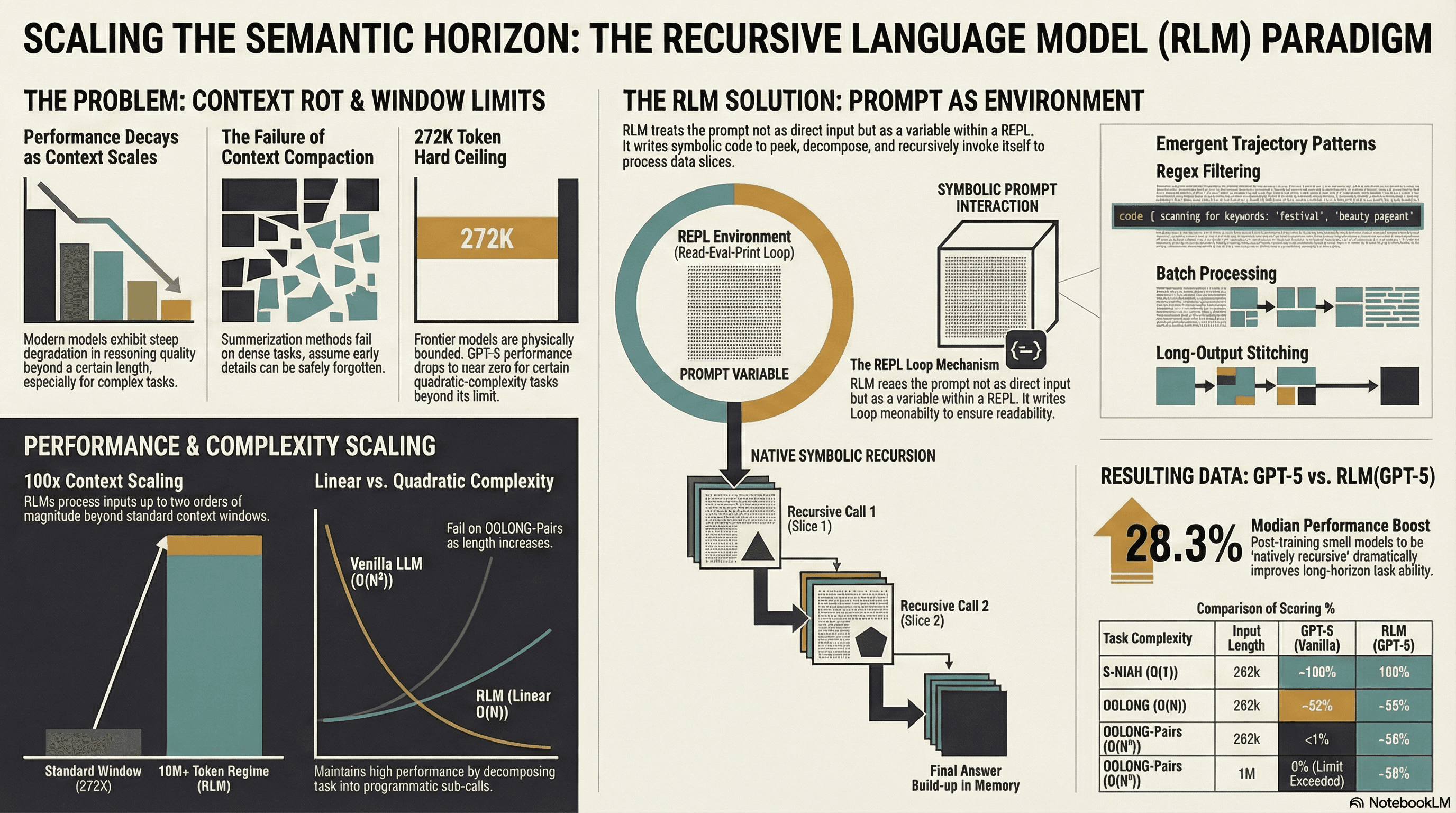
Let me build up the intuition step by step.The root problem: A user query like "how do I fix a leaky pipe?" and a document containing "plumbing maintenance procedures for residential water systems" might mean the same thing — but their vector representations land in different neighborhoods. Zero-shot retrieval compares short + sparse query embeddings to long + rich document embeddings. That mismatch is structural.
So the question becomes: how do we close this gap?
First principles thinking — three possible strategies:
Strategy 1 — Bring the document closer to the query. Summarize or compress documents into query-like representations. (This is what dense retrieval models are trained to do.) But it's hard to do at inference time.
Strategy 2 — Bring the query closer to the document. Expand the query — add synonyms, related terms, more context. Old-school NLP did this (query expansion). But how do you know what to expand with?
Strategy 3 — Bypass the gap entirely. What if instead of comparing queries to documents, we compared documents to documents?
That third insight is the key leap. Let's follow it.This is the core idea of HyDE — Hypothetical Document Embeddings.
The key insight unpacked:
Instead of asking *"find documents similar to this query"*, HyDE asks *"find documents similar to what the answer would look like."*
The LLM generates a hypothetical document — essentially, a plausible answer to the query. It doesn't matter if the answer is factually correct. What matters is that it lives in the same vector space distribution as real documents. A hallucinated but plausible paragraph about pipe leaks will structurally resemble a real plumbing article far more than the original query "how do I fix a leaky pipe?" ever could.
Then you embed that hypothetical doc and use it as your search vector.

Why does this work, from first principles?
Embedding models are trained on documents. Their geometry reflects document-level patterns — vocabulary, phrasing, density, style. A short query is an outlier in that space. A paragraph, even a fabricated one, is a native inhabitant.
You're essentially using the LLM as a query-to-document translator, converting a sparse user intent signal into something the embedding space is comfortable navigating.
The beautiful tradeoff:
HyDE offloads the semantic interpretation burden to the LLM (which is good at understanding intent) and lets the embedding model do what it's good at (comparing document-like things to other document-like things). The two models play to their strengths.
Final Pipeline

So HyDE is actually two separate LLM calls doing two completely different jobs:
LLM call 1 — be creative, hallucinate freely, just sound like a document
LLM call 2 — be accurate, stick to what the retrieved docs actually say
That separation of concerns is the elegance of it.
Abstract

Research Paper : Precise Zero-Shot Dense Retrieval without Relevance Label